
Base Models vs Finetunes & LoRAs
Do they really improve output?


One of the great aspects of open-source diffusion models is the way the community can tweak and tune these models, creating versions specific to styles, characters, details and composition.
If you are new to the world of ComfyUI and open source models this fast moving collection of LoRAs (Low Rank Adaption models) and the more heavy weight finetunes, all created by dedicated individuals and groups, is an interesting area to experiment with.
However, given the base models such as Qwen Image, Flux.1 Krea and HiDream are developed by large organisations using thousands upon thousands of hours of training time, can these lower scale refined models and LoRAs really make an improvement to the base model?
Finetune or LoRA?
The world of finetuning and LoRA generation is somewhat confusing due to the way new models are referenced. Alongside straightforward, standalone LoRAs, there are LoRAs merged into base models, and full finetunes, both of which are often listed as ‘checkpoints’ without the clarification of ‘checkpoint-merged’ or ‘checkpoint-trained’. On top of this you often come across ‘finetunes’ which are actually just LoRAs merged into a base model so it all gets a bit messy.
The difference between a finetune and a LoRA lays in the technical details of parameters and training. In general a finetune should provide a better result than a LoRA as it uses a wider set of parameters (and hence is a lot more complicated to train) but the quality of the training plays a big part and there are use-cases for both LoRAs and finetunes, with no guarantee that one is better than the other.
For the purpose of this post the end game is the same - to direct the model to produce a particular style, improve an aspect such as realism, or create a very focused output such as a consistent character.
A character LoRA is very specific and when well trained can create high quality results so its purpose and value is very clear, albeit the range in quality of these forms of LoRAs is large. They are also relatively easy to create for certain base models, as covered in a previous post - How to Train a LoRA.
The position around style and attribute LoRAs along with finetunes is more nuanced. Practically LoRAs can be more flexible as you can control the strength of a LoRA, mix multiple LoRAs, and often use different ‘trigger’ words in the prompt to call out various features of the LoRA. However, LoRAs do slow down processing and can interact in undesirable ways. One reason people merge LoRAs with their base model to form a checkpoint is to improve performance. Finetunes (and LoRA merged checkpoints) are just like using a new model - no strength control or trigger words.
Using Finetunes and LoRAs
Using a finetune model is straight forward, many being offered in a standard safetensors format file, which just drops into the model loader in place of the standard base model. There are a couple of points to note:
Some of these models are pruned, meaning they end up being smaller in size than the original model which can help if you are limited on VRAM.
Models listed as checkpoints may include VAE and Clip models and can be loaded using the Checkpoint Loader node, however, I find many which are listed as checkpoints are actually only the main model.
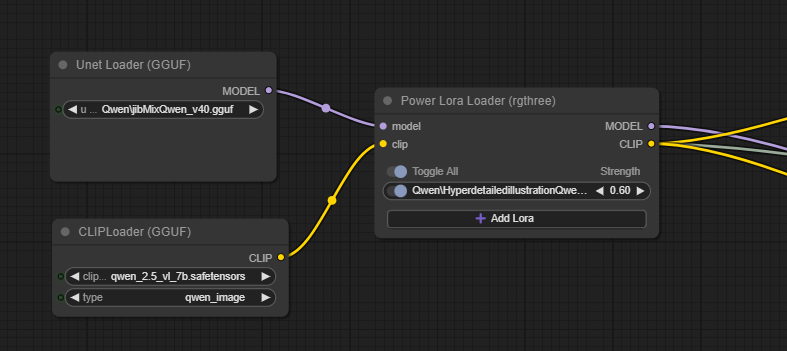
Increasingly finetunes are offered in a quantised version, normally as a GGUF file. These can be loaded using the UNET Loader (GGUF) node - I try to go with Q8 or Q6 versions which offer good quality and are often still smaller than the FP8 versions.
Some finetunes are tailored to specific sampler/scheduler combinations so it is worth noting these settings from the finetune information.
For LoRAs they can be loaded into the workflow using any of the LoRA loader nodes. I tend to use Power Lora Loader (rgthree) but there are several others. It is important to note the recommended strength and trigger words (if needed).
Not All Finetunes and LoRAs Are Created Equal
Outside of these technical aspects the big question is whether they do improve output and from my experience the answer is mixed.
I find many of the LoRAs and finetunes on sites such as Civitai (no longer directly accessible from the UK) and HuggingFace can introduce issues which reduce the quality of the output, everything from patterns across the image through to errors in composition, meaning more renders to produce one good output.
I think the second problem with some of these models stems from limited training sets, leading to narrow styles and the issue of all outputs looking very similar compared to the original base model. There is also probably an element of a sort of ‘confirmation bias’ where someone will select a training set which consists of images they like and either intentionally or unintentionally overly narrow the output of the model.
So far this sounds a little negative, but it is not all bad news, there are excellent LoRAs and finetunes out there, they just take some hunting down and testing with the acknowledgement that a large proportion will get discarded.
Real World Examples
I am not intending to recommend a list of LoRAs and finetunes, partly as it is an ever shifting list, and also because it is quite a subjective and personal area, however, I am including some examples below. These all use the same workflow, prompt, seed and settings just with different models or LoRAs.


This example uses the standard Qwen Image model for the first image and the finetuned JibMixQwen model for the second image. JibMixQwen aims to provide more realism and detail, and in this case outputs a much richer image. Also worth noting that the standard Qwen Image model will tend to default to Asian characters whereas the JibMixQwen model is orientated to Caucasian. I have been a fan of the various JibMix models for a while, including the Flux varieties, they tend to work well with photorealistic images.
Next up an anime example.



The first image is standard Qwen Image, the second image is using a hyperdetail illustration LoRA and the third uses the Lah Mysterious Qwen finetune. In this case the LoRA has had a small impact but hasn’t made a significant difference whereas the finetune has created quite a different output. Lah Mysterious Qwen can create some really good looking images but it does have a relatively narrow style. Anime styling is an area where good LoRAs or finetunes can really make a difference as the base models are broad and usually photorealistic orientated.
Flux.1 Krea Dev is another base model where there are now quite a few finetunes and lots of LoRAs available.




In this case both of the finetuned models tend towards an arty portrait style and the addition of a ‘Sean Archer’ LoRA pushes this further with JibMixSPRO
Adding the ‘Sean Archer’ LoRA to the other two models is an interesting test.


In both cases you can see how it is acting as a ‘style enhancer’ and running with the Fascium model it has changed the composition more significantly, taking it towards the output of JibMixSPRO This effect with the Sean Archer LoRA perhaps suggests some narrowing of output due to a limited range of training data on that LoRA.
It’s worth noting that there are a huge number of finetunes and LoRAs available for Flux.1 Dev as it is relatively easy to train using that model. There are some really good finetunes which I used to use, however, since the release of Flux.1 Krea and then Qwen Image I have not tended to use Flux.1 Dev based models for photorealism as much, however, in other areas it is still a good option.


In this example prompting for an anime styled illustration the original Flux.1 Dev model is still quite photorealistic but the addition of the AnimeArtV3 LoRA takes it to a more detailed illustration, albeit with changes to the composition. You may notice that in the base Flux.1 Dev image there are anatomical issues with the feet in particular, adding the LoRA has changed this with the man wearing shoes instead!
Running this again using JibMixFlux as the model we get the following output.


The JibMIx version is not that dissimilar to the base model, remaining fairly photorealistic and with some anatomical issues (notice the extra hand). In this case adding in the AnimeArtV3 LoRA has had less of an impact and not fixed any of the anatomical issues.
LoRAs are tied to the model they were trained with. If a finetune is used which is based on the same base model as the LoRA, then the LoRA should work but it is not a given. In some cases the LoRA may produce different results, in others it may not work at all, or at a reduced strength (which could be compensated by pushing up the LoRA strength in its settings).
Summary
Having a whole host of different finetunes and LoRAs can be a pain to manage as well as consuming a large amount of disc space but having a curated collection is worth the research and testing time.
Many are likely to be discarded, and different finetune models or LoRAs are unlikely to compensate for a poor prompt and settings, but in the right situation they can add an extra level to the output.
This is not surprising as the base models are very broad, so having finetuned models which are more tuned to specific styles is a great option, provided the finetune hasn’t been created with too narrow a training set or poorly created such that it creates more issues than it solves.